In the previous blog posts you have seen how to create a disaster recovery for on-premises Oracle Database by creating a standby database in Oracle Cloud. Sometimes, you might not need to create a standby database, but just store the backup of your database in Oracle Cloud Storage and then use it to create a database in the cloud in the feature. In this blog post I will show you how to take backup of on-premises database to Oracle Cloud Storage and use it to perform a disaster recovery by restoring/recovering from backup to the instance in the cloud and perform recovery of on-premises database using backups stored in the cloud storage using RMAN.
First of all, we need to download and install a backup model to on-premises db. Open the following link and download Oracle Database Cloud Backup Module :
http://www.oracle.com/technetwork/database/availability/oracle-cloud-backup-2162729.html
Create folder to store wallets and lib file, extract the zip file and install it:
[oracle@ocm11g ~]$ mkdir wallet lib
[oracle@ocm11g tmp]$ java -jar opc_install.jar -serviceName Storage -identityDomain yourIdentityDomain -opcID YourOpcId -opcPass YourOpcPassword -walletDir /home/oracle/wallet -libDir /home/oracle/lib
Oracle Database Cloud Backup Module Install Tool, build 2016-10-07
Oracle Database Cloud Backup Module credentials are valid.
Oracle Database Cloud Backup Module wallet created in directory /home/oracle/wallet.
Oracle Database Cloud Backup Module initialization file /u03/oracle/product/11.2.4/db_1/dbs/opcPROD.ora created.
Downloading Oracle Database Cloud Backup Module Software Library from file opc_linux64.zip.
Downloaded 26528348 bytes in 12 seconds. Transfer rate was 2210695 bytes/second.
Download complete.
[oracle@ocm11g tmp]$
The name of on-premises database is PROD. Now connect to RMAN and change the following configurations. Configure the channel to use SBT library which enable to store backups to the cloud (libopc.so) and provide OPC_FILE destination that contains Oracle Backup Cloud Service container URL.
RMAN> CONFIGURE CHANNEL DEVICE TYPE ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u03/oracle/product/11.2.4/db_1/dbs/opcPROD.ora)’;
new RMAN configuration parameters:
CONFIGURE CHANNEL DEVICE TYPE ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u03/oracle/product/11.2.4/db_1/dbs/opcPROD.ora)’;
new RMAN configuration parameters are successfully stored
Enable autobackup of controlfile:
RMAN> CONFIGURE CONTROLFILE AUTOBACKUP ON;
new RMAN configuration parameters:
CONFIGURE CONTROLFILE AUTOBACKUP ON;
new RMAN configuration parameters are successfully stored
Set the high compression for backups to consume less space in the cloud storage:
RMAN> CONFIGURE COMPRESSION ALGORITHM ‘HIGH’;
new RMAN configuration parameters:
CONFIGURE COMPRESSION ALGORITHM ‘HIGH’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
new RMAN configuration parameters are successfully stored
Change the default channel to tape (media -> Oracle Cloud Backup Storage)
RMAN> CONFIGURE DEFAULT DEVICE TYPE TO ‘SBT_TAPE’;
new RMAN configuration parameters:
CONFIGURE DEFAULT DEVICE TYPE TO ‘SBT_TAPE’;
new RMAN configuration parameters are successfully stored
RMAN>
Now connect to RMAN and run SHOW ALL command to see the backup configurations:
[oracle@ocm11g ~]$ rman target /
RMAN> show all;
using target database control file instead of recovery catalog
RMAN configuration parameters for database with db_unique_name PROD are:
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default
CONFIGURE BACKUP OPTIMIZATION OFF; # default
CONFIGURE DEFAULT DEVICE TYPE TO ‘SBT_TAPE’;
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE SBT_TAPE TO ‘%F’; # default
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO ‘%F’; # default
CONFIGURE DEVICE TYPE SBT_TAPE PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default
CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE SBT_TAPE TO 1; # default
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE SBT_TAPE TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE CHANNEL DEVICE TYPE ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u03/oracle/product/11.2.4/db_1/dbs/opcPROD.ora)’;
CONFIGURE MAXSETSIZE TO UNLIMITED; # default
CONFIGURE ENCRYPTION FOR DATABASE OFF; # default
CONFIGURE ENCRYPTION ALGORITHM ‘AES128’; # default
CONFIGURE COMPRESSION ALGORITHM ‘HIGH’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE;
CONFIGURE ARCHIVELOG DELETION POLICY TO NONE; # default
CONFIGURE SNAPSHOT CONTROLFILE NAME TO ‘/u03/oracle/product/11.2.4/db_1/dbs/snapcf_PROD.f’; # default
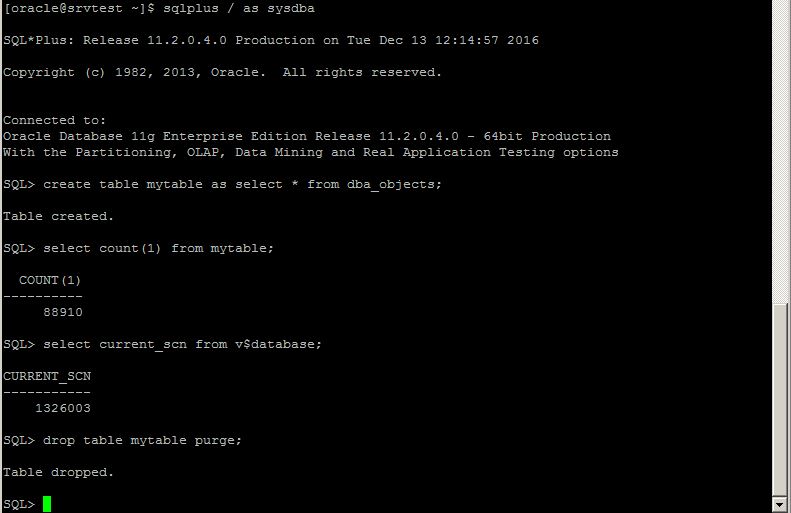
Before taking the backup, create a table at on-premises database. We will query it after disaster recovery in the cloud db.
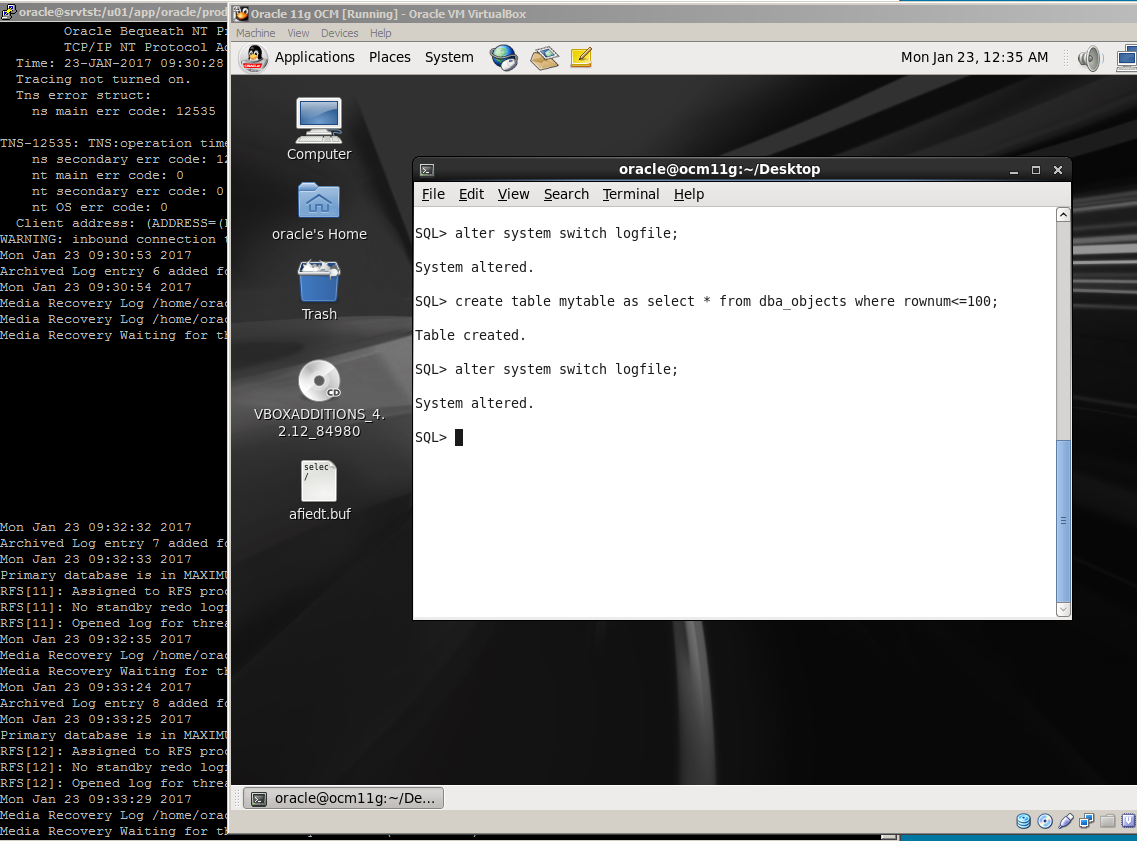
SQL> create table mytable as select * from dba_objects where rownum<=100;
Table created.
SQL> select count(1) from mytable;
COUNT(1)
———-
100
SQL>
Now enable encryption (set the password for backups) and take backup of the database:
RMAN> set encryption on identified by “mypass” only;
executing command: SET encryption
RMAN> backup database plus archivelog;
Starting backup at 10-FEB-17
current log archived
allocated channel: ORA_SBT_TAPE_1
channel ORA_SBT_TAPE_1: SID=33 device type=SBT_TAPE
channel ORA_SBT_TAPE_1: Oracle Database Backup Service Library VER=3.16.9.21
channel ORA_SBT_TAPE_1: starting archived log backup set
channel ORA_SBT_TAPE_1: specifying archived log(s) in backup set
input archived log thread=1 sequence=48 RECID=71 STAMP=935603816
channel ORA_SBT_TAPE_1: starting piece 1 at 10-FEB-17
channel ORA_SBT_TAPE_1: finished piece 1 at 10-FEB-17
piece handle=17rs8bjd_1_1 tag=TAG20170210T175700 comment=API Version 2.0,MMS Version 3.16.9.21
channel ORA_SBT_TAPE_1: backup set complete, elapsed time: 00:00:25
Finished backup at 10-FEB-17
Starting backup at 10-FEB-17
using channel ORA_SBT_TAPE_1
channel ORA_SBT_TAPE_1: starting full datafile backup set
channel ORA_SBT_TAPE_1: specifying datafile(s) in backup set
input datafile file number=00001 name=/u03/oracle/oradata/PROD/system01.dbf
input datafile file number=00002 name=/u03/oracle/oradata/PROD/sysaux01.dbf
input datafile file number=00003 name=/u03/oracle/oradata/PROD/undotbs01.dbf
input datafile file number=00004 name=/u03/oracle/oradata/PROD/users01.dbf
channel ORA_SBT_TAPE_1: starting piece 1 at 10-FEB-17
channel ORA_SBT_TAPE_1: finished piece 1 at 10-FEB-17
piece handle=18rs8bk6_1_1 tag=TAG20170210T175726 comment=API Version 2.0,MMS Version 3.16.9.21
channel ORA_SBT_TAPE_1: backup set complete, elapsed time: 02:57:07
Finished backup at 10-FEB-17
Starting backup at 10-FEB-17
current log archived
using channel ORA_SBT_TAPE_1
channel ORA_SBT_TAPE_1: starting archived log backup set
channel ORA_SBT_TAPE_1: specifying archived log(s) in backup set
input archived log thread=1 sequence=49 RECID=72 STAMP=935605482
input archived log thread=1 sequence=50 RECID=73 STAMP=935614475
channel ORA_SBT_TAPE_1: starting piece 1 at 10-FEB-17
channel ORA_SBT_TAPE_1: finished piece 1 at 10-FEB-17
piece handle=1ars8m0c_1_1 tag=TAG20170210T205435 comment=API Version 2.0,MMS Version 3.16.9.21
channel ORA_SBT_TAPE_1: backup set complete, elapsed time: 00:09:25
Finished backup at 10-FEB-17
Starting Control File and SPFILE Autobackup at 10-FEB-17
piece handle=c-345613202-20170210-02 comment=API Version 2.0,MMS Version 3.16.9.21
Finished Control File and SPFILE Autobackup at 10-FEB-17
RMAN>
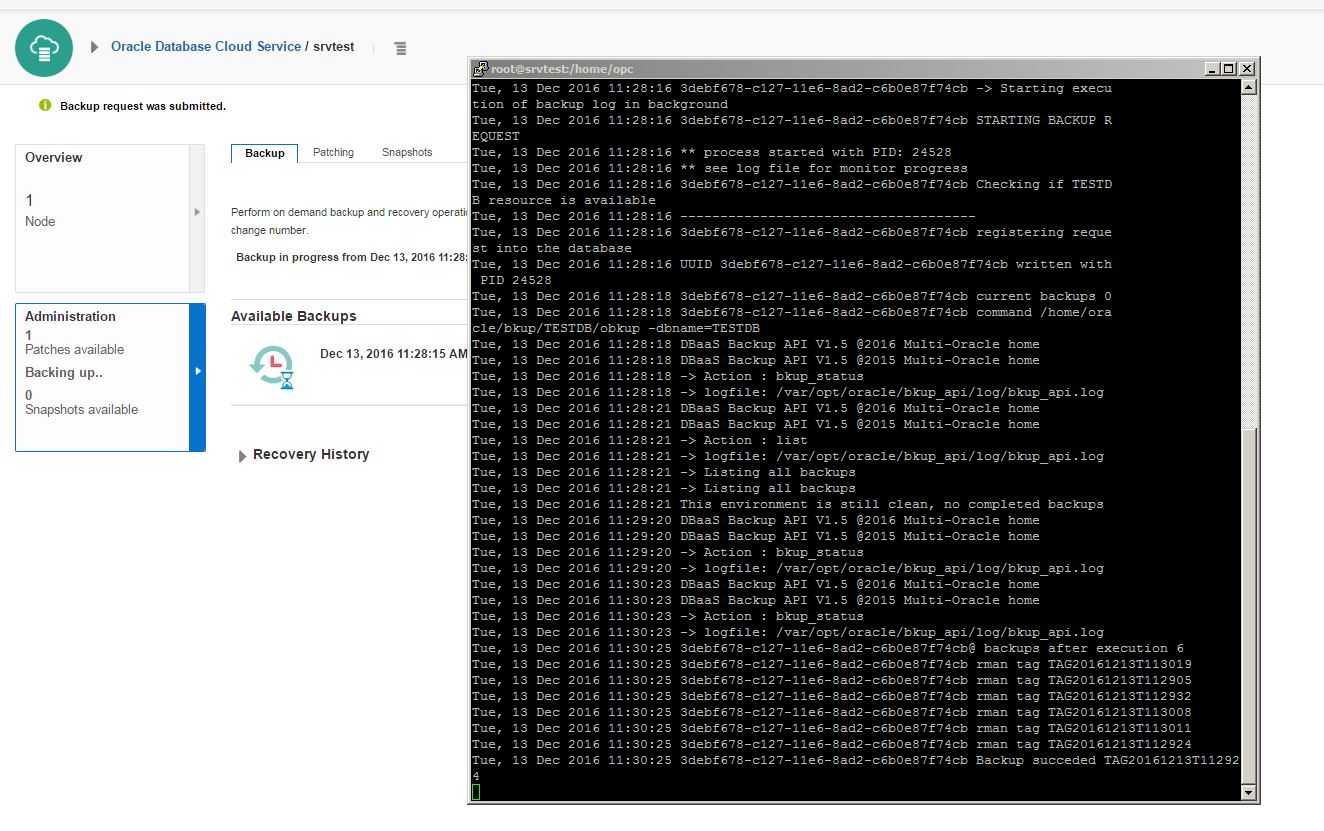
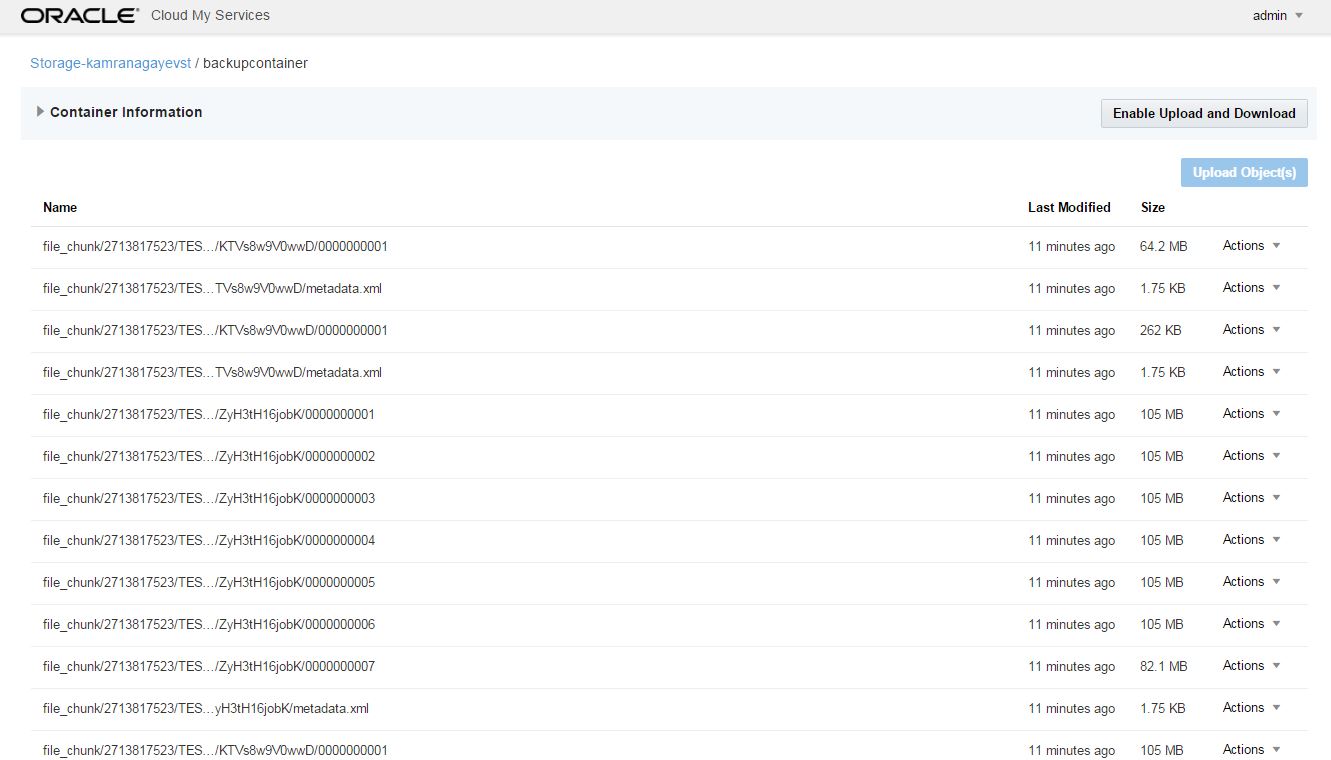
The backup command completed successfully and all backups are stored in Oracle Cloud Backup Storage.
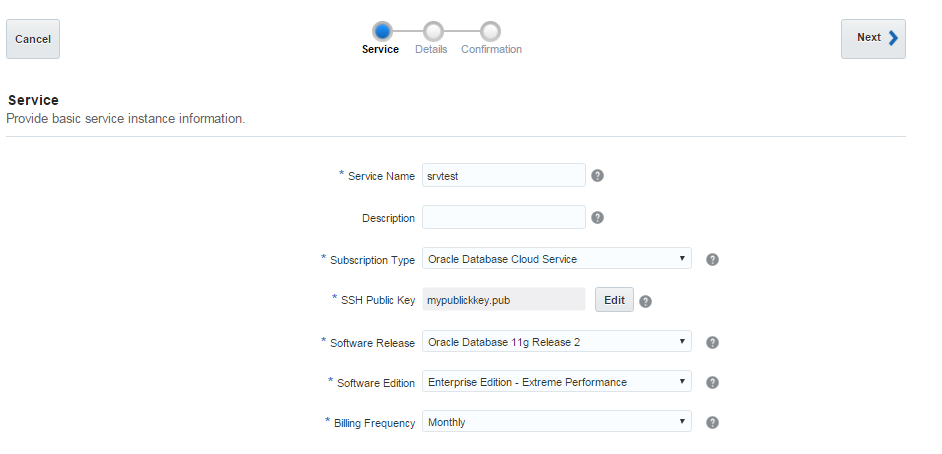
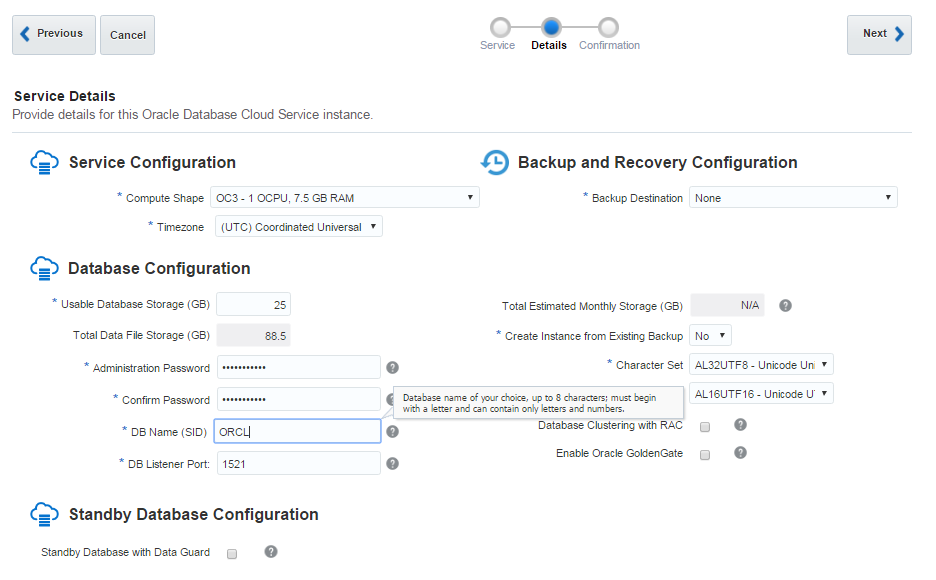
Now let’s perform a disaster recovery in the cloud machine. Create a new cloud database instance, configure SSH connection from on-premises to the cloud host. Copy opc_install.zip file you have downloaded from OTN to the cloud host and install it as you did it at on-premises host. Drop the database if there’s any, connect to RMAN and start it in NOMOUNT mode. Provide the RMAN password, allocate a channel as you did at on-premises database and restore the spfile:
RMAN> STARTUP NOMOUNT;
RMAN> set decryption identified by “mypass”;
executing command: SET decryption
using target database control file instead of recovery catalog
RMAN> run
2> {
3> allocate channel t1 type ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u01/app/oracle/product/11.2.0/dbhome_1/dbs/opcPROD.ora)’;
4> set dbid=345613202;
5> restore spfile to pfile ‘/tmp/pfile.ora’ from autobackup;
6> }
allocated channel: t1
channel t1: SID=171 device type=SBT_TAPE
channel t1: Oracle Database Backup Service Library VER=3.16.9.21
executing command: SET DBID
Starting restore at 11-FEB-17
channel t1: looking for AUTOBACKUP on day: 20170211
channel t1: looking for AUTOBACKUP on day: 20170210
channel t1: AUTOBACKUP found: c-345613202-20170210-02
channel t1: restoring spfile from AUTOBACKUP c-345613202-20170210-02
channel t1: SPFILE restore from AUTOBACKUP complete
Finished restore at 11-FEB-17
released channel: t1
RMAN>
Server parameter file is restored. If you need to specify different location for some parameters, create a readable parameter file from it, make your changes, create a server parameter file from it and start the database in NOMOUNT mode using the restored (and modified) spfile.
SQL> startup nomount force;
ORACLE instance started.
Total System Global Area 1235959808 bytes
Fixed Size 2252784 bytes
Variable Size 385875984 bytes
Database Buffers 838860800 bytes
Redo Buffers 8970240 bytes
SQL> exit
Now restore controlfile from autobackup:
RMAN> set decryption identified by “mypass”;
executing command: SET decryption
RMAN> run
2> {
3> allocate channel t1 type ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u01/app/oracle/product/11.2.0/dbhome_1/dbs/opcPROD.ora)’;
4> set dbid=345613202;
5> restore controlfile from autobackup;
6> }
allocated channel: t1
channel t1: SID=134 device type=SBT_TAPE
channel t1: Oracle Database Backup Service Library VER=3.16.9.21
executing command: SET DBID
Starting restore at 11-FEB-17
channel t1: looking for AUTOBACKUP on day: 20170211
channel t1: looking for AUTOBACKUP on day: 20170210
channel t1: AUTOBACKUP found: c-345613202-20170210-02
channel t1: restoring control file from AUTOBACKUP c-345613202-20170210-02
channel t1: control file restore from AUTOBACKUP complete
output file name=/u04/app/oracle/oradata/control01.ctl
output file name=/u04/app/oracle/oradata/control02.ctl
Finished restore at 11-FEB-17
released channel: t1
RMAN>
Controlfile are restored. Start the database in MOUNT mode and restore the datafiles. Specify a new folder using SET NEWNAME FOR DATABASE TO command as follows:
RMAN> run
2> {
3> allocate channel t1 type ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u01/app/oracle/product/11.2.0/dbhome_1/dbs/opcPROD.ora)’;
4> set newname for database to ‘/u04/app/oracle/oradata/%U.dbf’;
5> restore database;
6> switch datafile all;
7> }
allocated channel: t1
channel t1: SID=133 device type=SBT_TAPE
channel t1: Oracle Database Backup Service Library VER=3.16.9.21
executing command: SET NEWNAME
Starting restore at 11-FEB-17
Starting implicit crosscheck backup at 11-FEB-17
Crosschecked 1 objects
Finished implicit crosscheck backup at 11-FEB-17
Starting implicit crosscheck copy at 11-FEB-17
Crosschecked 2 objects
Finished implicit crosscheck copy at 11-FEB-17
searching for all files in the recovery area
cataloging files…
no files cataloged
channel t1: starting datafile backup set restore
channel t1: specifying datafile(s) to restore from backup set
channel t1: restoring datafile 00001 to /u04/app/oracle/oradata/data_D-PROD_TS-SYSTEM_FNO-1.dbf
channel t1: restoring datafile 00002 to /u04/app/oracle/oradata/data_D-PROD_TS-SYSAUX_FNO-2.dbf
channel t1: restoring datafile 00003 to /u04/app/oracle/oradata/data_D-PROD_TS-UNDOTBS1_FNO-3.dbf
channel t1: restoring datafile 00004 to /u04/app/oracle/oradata/data_D-PROD_TS-USERS_FNO-4.dbf
channel t1: reading from backup piece 18rs8bk6_1_1
channel t1: piece handle=18rs8bk6_1_1 tag=TAG20170210T175726
channel t1: restored backup piece 1
channel t1: restore complete, elapsed time: 00:00:45
Finished restore at 11-FEB-17
datafile 1 switched to datafile copy
input datafile copy RECID=14 STAMP=935693831 file name=/u04/app/oracle/oradata/data_D-PROD_TS-SYSTEM_FNO-1.dbf
datafile 2 switched to datafile copy
input datafile copy RECID=15 STAMP=935693831 file name=/u04/app/oracle/oradata/data_D-PROD_TS-SYSAUX_FNO-2.dbf
datafile 3 switched to datafile copy
input datafile copy RECID=16 STAMP=935693831 file name=/u04/app/oracle/oradata/data_D-PROD_TS-UNDOTBS1_FNO-3.dbf
datafile 4 switched to datafile copy
input datafile copy RECID=17 STAMP=935693831 file name=/u04/app/oracle/oradata/data_D-PROD_TS-USERS_FNO-4.dbf
released channel: t1
RMAN>
Now run ALTER DATABASE RENAME FILE command to rename redo log files:
SQL> alter database rename file ‘/u03/oracle/oradata/PROD/redo03.log’ to ‘/u04/app/oracle/oradata/redo03.log’;
Database altered.
SQL> alter database rename file ‘/u03/oracle/oradata/PROD/redo02.log’ to ‘/u04/app/oracle/oradata/redo02.log’;
Database altered.
SQL> alter database rename file ‘/u03/oracle/oradata/PROD/redo01.log’ to ‘/u04/app/oracle/oradata/redo01.log’;
Database altered.
SQL>
Now run RECOVER DATABASE command to recover the database and open the database:
RMAN> set decryption identified by “mypass”;
executing command: SET decryption
RMAN> run
2> {
3> allocate channel t1 type ‘SBT_TAPE’ PARMS ‘SBT_LIBRARY=/home/oracle/lib/libopc.so ENV=(OPC_PFILE=/u01/app/oracle/product/11.2.0/dbhome_1/dbs/opcPROD.ora)’;
4> recover database;
5> }
allocated channel: t1
channel t1: SID=125 device type=SBT_TAPE
channel t1: Oracle Database Backup Service Library VER=3.16.9.21
Starting recover at 11-FEB-17
starting media recovery
channel t1: starting archived log restore to default destination
channel t1: restoring archived log
archived log thread=1 sequence=49
channel t1: restoring archived log
archived log thread=1 sequence=50
channel t1: reading from backup piece 1ars8m0c_1_1
channel t1: piece handle=1ars8m0c_1_1 tag=TAG20170210T205435
channel t1: restored backup piece 1
channel t1: restore complete, elapsed time: 00:00:07
archived log file name=/u03/app/oracle/fast_recovery_area/PROD/archivelog/2017_02_11/o1_mf_1_49_d9yqs878_.arc thread=1 sequence=49
channel default: deleting archived log(s)
archived log file name=/u03/app/oracle/fast_recovery_area/PROD/archivelog/2017_02_11/o1_mf_1_49_d9yqs878_.arc RECID=75 STAMP=935693995
archived log file name=/u03/app/oracle/fast_recovery_area/PROD/archivelog/2017_02_11/o1_mf_1_50_d9yqs8cn_.arc thread=1 sequence=50
channel default: deleting archived log(s)
archived log file name=/u03/app/oracle/fast_recovery_area/PROD/archivelog/2017_02_11/o1_mf_1_50_d9yqs8cn_.arc RECID=74 STAMP=935693994
unable to find archived log
archived log thread=1 sequence=51
released channel: t1
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of recover command at 02/11/2017 19:00:00
RMAN-06054: media recovery requesting unknown archived log for thread 1 with sequence 51 and starting SCN of 1153764
RMAN> alter database open resetlogs;
database opened
RMAN>
Connect to SQL*Plus and query the table you have created before taking a backup at on-premises database:
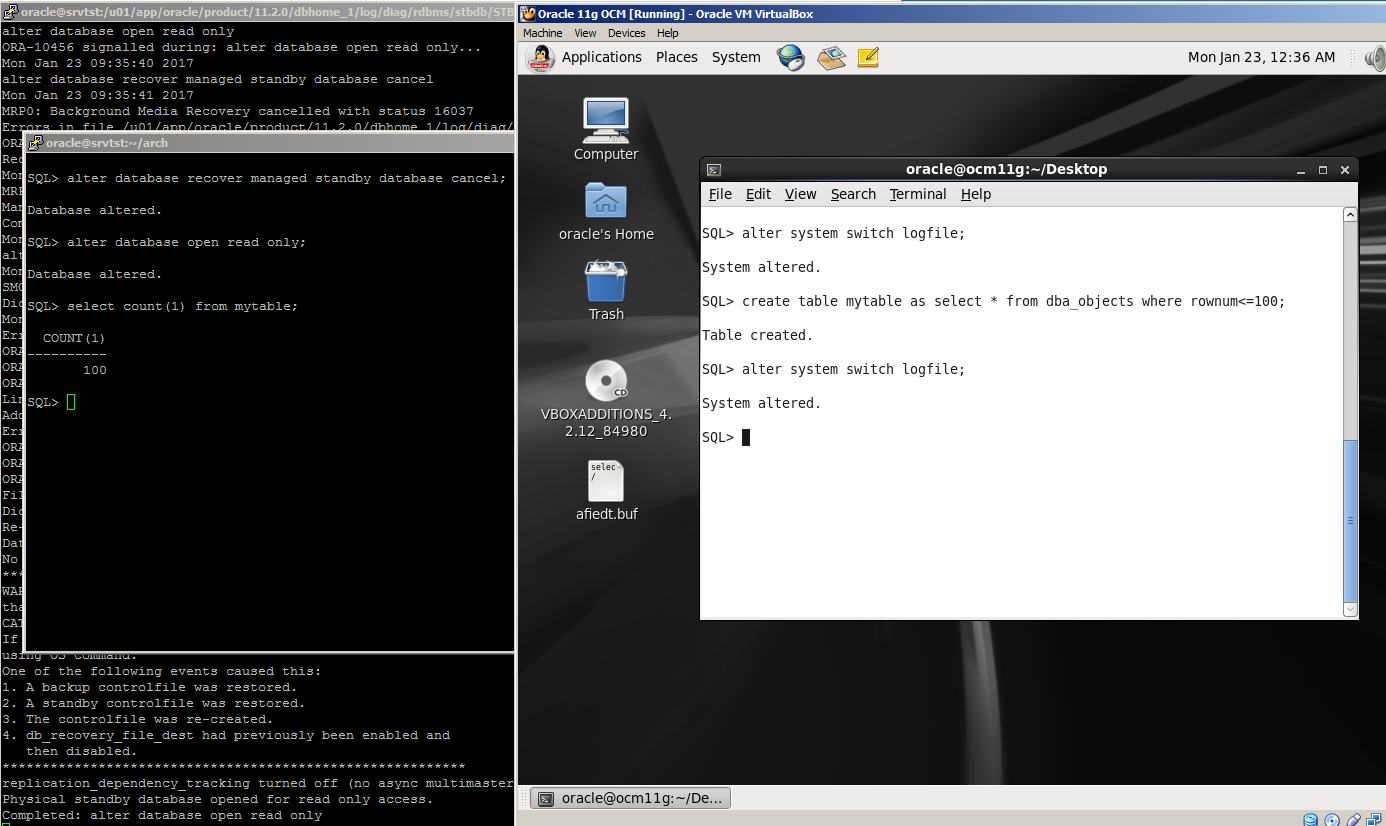
SQL> select count(1) from mytable;
COUNT(1)
———-
100
SQL>
Great! We have successfully performed a disaster recovery of on-premises database to the cloud using RMAN backups stored in Oracle Cloud Storage!
Now let’s use backups stored in the cloud to perform a recovery to on-premises database. Let’s create a new table, take backup of the datafile, corrupt a block of the datafile and recover it from backups stored in the cloud.
SQL> create table test_table tablespace users as select * from dba_objects where rownum<=10;
Table created.
RMAN> set encryption on identified by “mypass” only;
executing command: SET encryption
RMAN> backup datafile 4;
Starting backup at 11-FEB-17
using channel ORA_SBT_TAPE_1
channel ORA_SBT_TAPE_1: starting full datafile backup set
channel ORA_SBT_TAPE_1: specifying datafile(s) in backup set
input datafile file number=00004 name=/u03/oracle/oradata/PROD/users01.dbf
channel ORA_SBT_TAPE_1: starting piece 1 at 11-FEB-17
channel ORA_SBT_TAPE_1: finished piece 1 at 11-FEB-17
piece handle=1drsaim0_1_1 tag=TAG20170211T141008 comment=API Version 2.0,MMS Version 3.16.9.21
channel ORA_SBT_TAPE_1: backup set complete, elapsed time: 00:00:45
Finished backup at 11-FEB-17
Starting Control File and SPFILE Autobackup at 11-FEB-17
piece handle=c-345613202-20170211-00 comment=API Version 2.0,MMS Version 3.16.9.21
Finished Control File and SPFILE Autobackup at 11-FEB-17
RMAN> exit
SQL> SELECT header_block FROM dba_segments WHERE segment_name=’TEST_TABLE’;
HEADER_BLOCK
————
170
SQL>
[oracle@ocm11g ~]$ dd of=/u03/oracle/oradata/PROD/users01.dbf bs=8192 conv=notrunc seek=170 <<EOF
> Corruption
> Corruption
> EOF
0+1 records in
0+1 records out
23 bytes (23 B) copied, 0.000147784 s, 156 kB/s
[oracle@ocm11g ~]$ sqlplus / as sysdba
SQL> alter system flush buffer_cache;
System altered.
SQL> select count(1) from test_table;
select count(1) from test_table
*
ERROR at line 1:
ORA-01578: ORACLE data block corrupted (file # 4, block # 170)
ORA-01110: data file 4: ‘/u03/oracle/oradata/PROD/users01.dbf’
SQL> select * from v$database_block_corruption;
FILE# BLOCK# BLOCKS CORRUPTION_CHANGE# CORRUPTIO
———- ———- ———- —————— ———
4 170 1 0 CORRUPT
Ok, we have a corrupted block. Now connect to RMAN and recover it:
RMAN> recover datafile 4 block 170;
Starting recover at 11-FEB-17
using channel ORA_SBT_TAPE_1
using channel ORA_DISK_1
channel ORA_SBT_TAPE_1: restoring block(s)
channel ORA_SBT_TAPE_1: specifying block(s) to restore from backup set
restoring blocks of datafile 00004
channel ORA_SBT_TAPE_1: reading from backup piece 1drsaim0_1_1
channel ORA_SBT_TAPE_1: piece handle=1drsaim0_1_1 tag=TAG20170211T141008
channel ORA_SBT_TAPE_1: restored block(s) from backup piece 1
channel ORA_SBT_TAPE_1: block restore complete, elapsed time: 00:00:15
starting media recovery
media recovery complete, elapsed time: 00:00:01
Finished recover at 11-FEB-17
RMAN> exit
[oracle@ocm11g ~]$ sqlplus / as sysdba
SQL> select count(1) from test_table;
COUNT(1)
———-
10
SQL>
As you see, we used backups stored in Oracle Cloud Storage to recover a corrupted block of on-premises database.
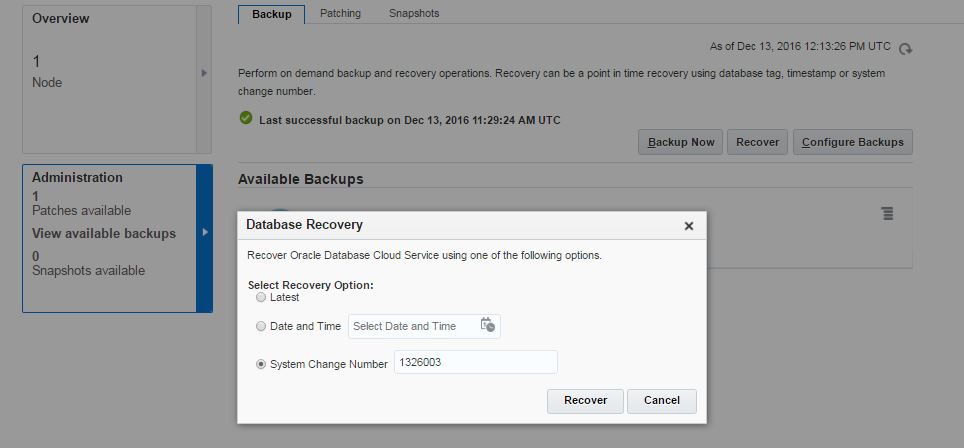
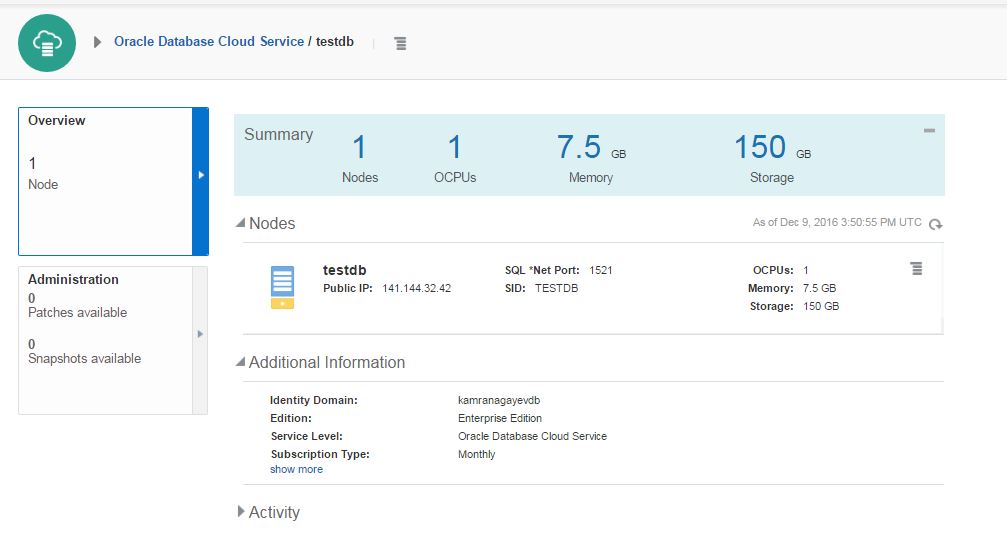 dministration section
dministration section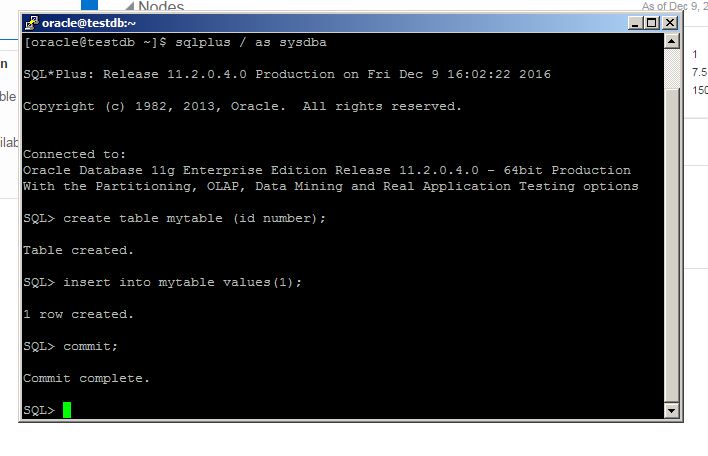
 l be created
l be created
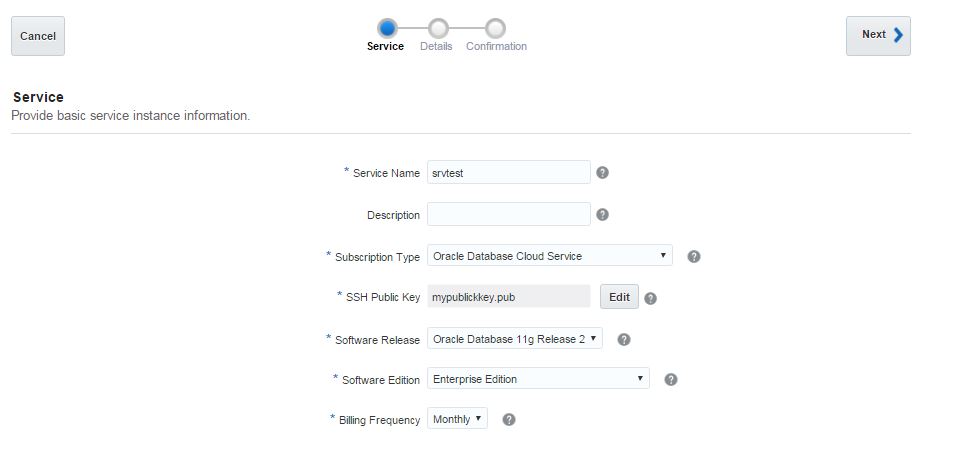
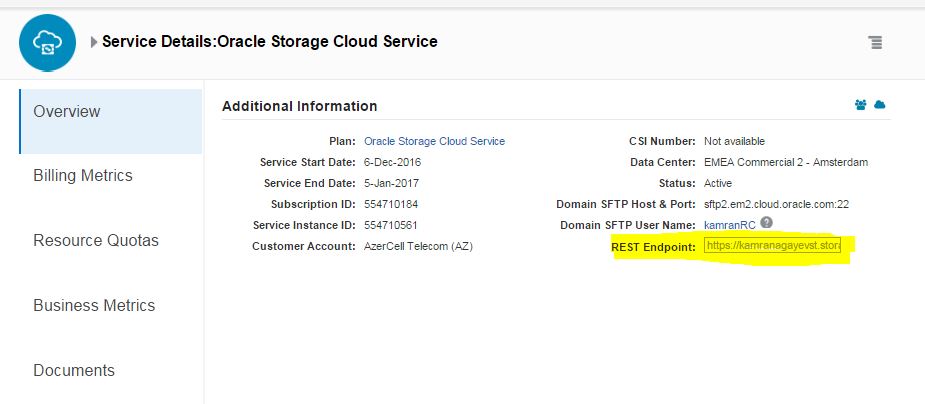
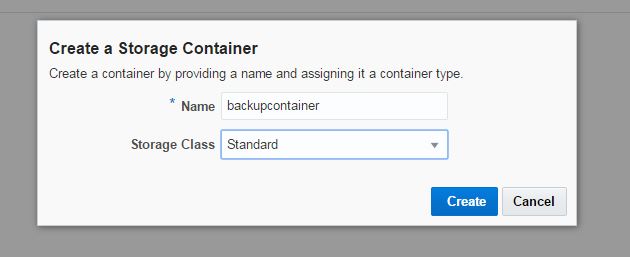
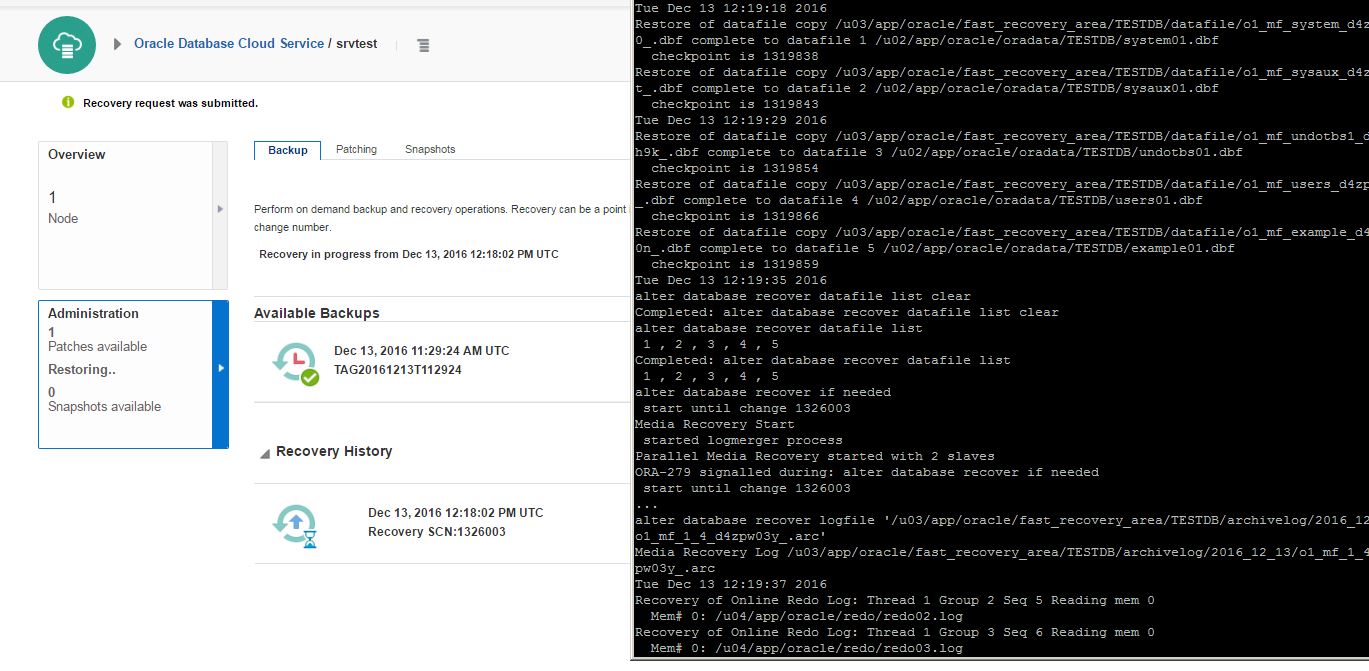
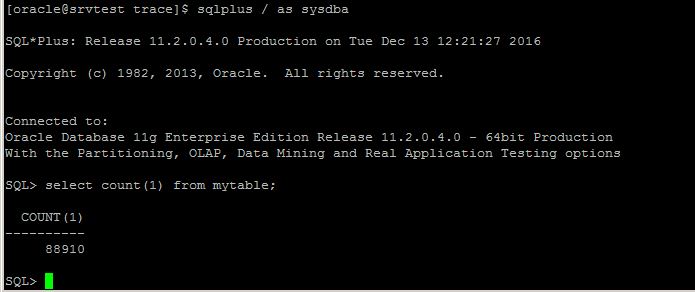
 in the database host:
in the database host: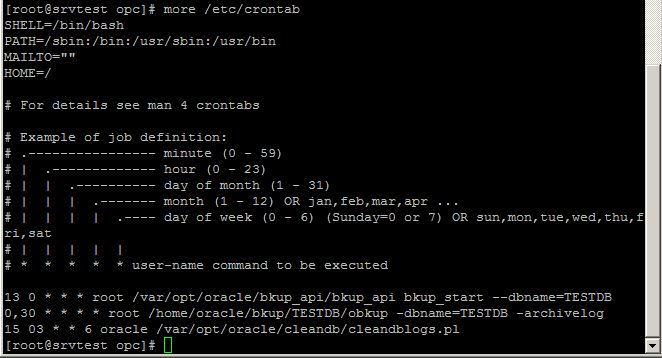
 I will keep updating the pdf and hope it will be much easier fo you to get all articles in one shot!
I will keep updating the pdf and hope it will be much easier fo you to get all articles in one shot!




















 Reviewing topics directly from my book helped me to be confident during the exam.
Reviewing topics directly from my book helped me to be confident during the exam.